GPT-5.5登場:OpenAI把AI競賽推向「會做事」的新階段
【 AI 新聞 | 編輯:Sandy】 OpenAI於2026年4月23日發布GPT-5.5,並在4月24日更新宣布GPT-5.5與GPT-5.5 Pro已可透過API使用,這使得這次發布不再只是一次模型升級,而是AI
【 AI 新聞 | 編輯:Sandy】 OpenAI於2026年4月23日發布GPT-5.5,並在4月24日更新宣布GPT-5.5與GPT-5.5 Pro已可透過API使用,這使得這次發布不再只是一次模型升級,而是AI
【 AI 新聞 | 編輯:Sandy】
OpenAI於2026年4月23日發布GPT-5.5,並在4月24日更新宣布GPT-5.5與GPT-5.5 Pro已可透過API使用,這使得這次發布不再只是一次模型升級,而是AI從「回答問題」走向「代理完成工作」的最新節點。根據OpenAI官方公告「Introducing GPT-5.5」(https://openai.com/index/introducing-gpt-5-5/),GPT-5.5主打知識工作、電腦操作、程式開發與工具使用能力,能在提示不完整、任務多步驟且含糊的情況下,更快理解使用者意圖,並持續跨工具推進任務。這句話的產業含義相當直接:大型語言模型的競爭焦點,正從單次對話的聰明程度,轉向誰能更可靠地在真實工作環境中完成複雜任務。
GPT-5.5的核心定位,是OpenAI所稱「用於真實工作的全新智慧層級」。它不只是生成文字、整理資料或寫一段程式碼,而是能研究資料、分析數據、建立文件與試算表、操作軟體,並在多個工具之間移動,直到任務完成。這與早期ChatGPT的差異在於,過去使用者往往需要把一個工作拆成許多步驟,再逐一要求模型執行;GPT-5.5則被設計成能處理較混亂、較接近真實職場的任務,例如一邊查資料,一邊驗證假設,再將結果整理成可交付的文件。
OpenAI在公告中特別強調,GPT-5.5在Codex與ChatGPT中的價值,體現在「代理式編碼」、知識工作、科學研究與電腦使用。這是一個重要轉折。AI公司過去常以模型能否通過數學、科學或常識測驗來說服市場,但企業真正付費的理由,往往不是模型能否回答一道難題,而是它能否節省工程師、分析師、律師、研究員或財務團隊的時間。OpenAI公布的內部案例也朝這個方向敘事:其財務團隊使用Codex審閱24,771份K-1稅務表格、總計71,637頁文件,並比前一年加速兩週;上市團隊員工則以自動化週報節省每週5至10小時。這些例子未必能直接代表所有企業場景,但它們指向一個更清楚的商業主張:AI不再只賣「答案」,而是賣「工作流壓縮」。
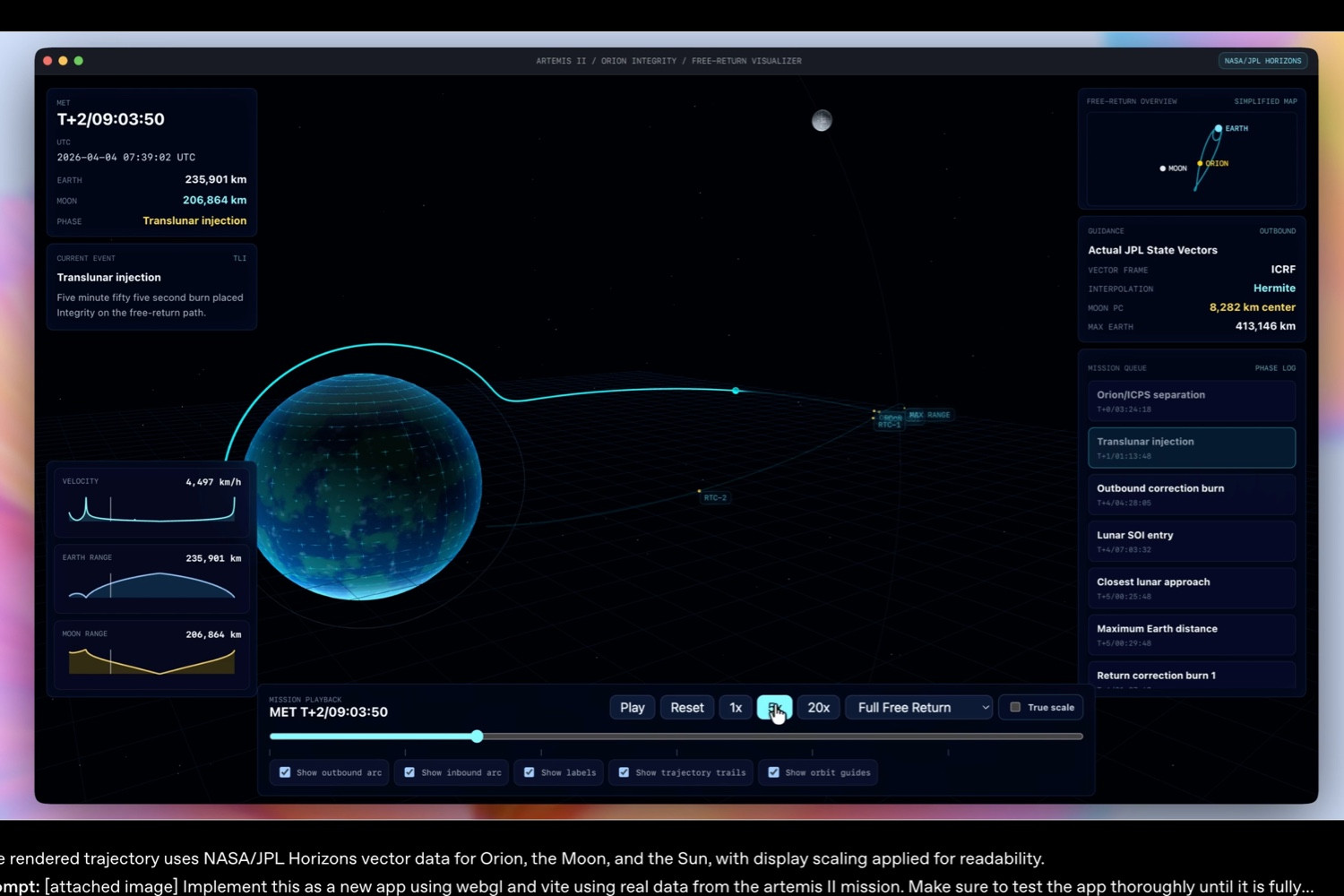
GPT-5.5的技術敘事可分為兩層。第一層是能力提升。OpenAI稱GPT-5.5在Terminal-Bench 2.0達到82.7%,在SWE-Bench Pro達到58.6%,在OSWorld-Verified達到78.7%,在GDPval則達到84.9%。這些數字本身需要謹慎解讀,因為基準測試常受到題庫、評測方式與實際使用場景差異影響;但它們仍反映出一個趨勢:模型正在從「會回答」往「會操作」與「會長時間推進」移動。尤其OSWorld-Verified測的是模型能否在真實電腦環境中自主操作,這比單純文字推理更接近企業軟體世界的現場。
第二層是成本與速度。OpenAI稱GPT-5.5在實際服務中的每token延遲可匹配GPT-5.4,同時智慧水準更高,且在Codex任務中以更少token完成工作。這是商業化上非常關鍵的一點。大型模型的能力若只能以更昂貴、更慢的推論換取,對企業而言便可能只是展示品;若能力提升同時伴隨更高推論效率,才有機會滲透到每天反覆發生的工作流程中。OpenAI還指出,GPT-5.5在API中標準價格為每100萬輸入token 5美元、每100萬輸出token 30美元,GPT-5.5 Pro則為每100萬輸入token 30美元、每100萬輸出token 180美元。這代表OpenAI仍維持高階模型的溢價策略,但試圖以更少token、更少重試與更高完成率來說服企業其總成本可被消化。
OpenAI此番發布的真正企圖,不只是再次贏得模型排行榜,而是讓ChatGPT、Codex與API成為企業工作場所中的代理層。GPT-5.5能跨已連接的工作工具採取行動,這意味著模型不再是孤立的對話框,而可能逐漸變成橫跨郵件、文件、程式碼庫、試算表、客服系統與內部資料庫的操作介面。若這一方向成立,AI平台的價值會從模型本身擴張到權限管理、資料連接、任務稽核、安全政策與工作流整合。
這也解釋了OpenAI為何在公告中大篇幅談安全與網路防禦。GPT-5.5被描述為具備更強的資安能力,OpenAI同時將其生物化學與資安能力在Preparedness Framework中視為High層級,並加強高風險資安請求的分類器與限制。這不是單純的公關補充,而是代理式AI商業化的必要條件。當模型可以操作工具、讀取內部資料、編寫與修補程式碼,它的便利性與風險同步上升。企業不會把核心工作交給一個只會聊天的模型;但也不會把核心工作交給一個無法被審計、無法被限制、無法被信任的代理人。
GPT-5.5發布的背景,是美國AI公司正集體把戰場推向代理式工作。Anthropic在官方公告「Introducing Claude Opus 4.7」(https://www.anthropic.com/news/claude-opus-4-7)中同樣強調更強的編碼、代理、視覺與多步驟任務能力,並把高風險資安用途的自動偵測與阻擋列為重點。這與OpenAI的敘事高度相似:最前沿模型不再只是更會說話,而是更能在長時間、多步驟、高不確定性的環境中維持目標。
Google的路線則更貼近其既有生態系。根據Google官方部落格「Gemini 3.1 Pro: A smarter model for your most complex tasks」(https://blog.google/innovation-and-ai/models-and-research/gemini-models/gemini-3-1-pro/),Gemini 3.1 Pro已向Gemini API、Vertex AI、Gemini應用與NotebookLM推出,主打複雜任務推理;而Google在「Deep Research Max: a step change for autonomous research agents」(https://blog.google/innovation-and-ai/models-and-research/gemini-models/next-generation-gemini-deep-research/)中,則把自主研究代理、MCP支援與原生視覺化作為長程研究工作流的賣點。相較之下,OpenAI的優勢在於ChatGPT的消費級入口與Codex的工程師心智占位;Google的優勢則是Workspace、雲端、搜尋與Android等龐大分發面。兩者競爭的核心,將不只是模型分數,而是誰能把AI嵌入更多日常工作觸點。
國際視角下,GPT-5.5也必須放在中美歐三條不同路徑中理解。中國的DeepSeek在官方文件「DeepSeek V4 Preview Release」(https://api-docs.deepseek.com/news/news260424)中宣布DeepSeek-V4 Preview開源,主打100萬token上下文、DeepSeek-V4-Pro的1.6兆總參數與49B活躍參數,以及DeepSeek-V4-Flash的高效率版本。這與OpenAI的閉源、高階、企業付費模式形成對照。中國模型的戰略意義不只在模型能力,也在於以開源、低成本與本土算力適配,降低對美國模型與NVIDIA硬體的依賴。若美國公司的護城河是產品化與雲端生態,中國公司的壓力測試則是成本曲線與供應鏈限制。
歐洲則呈現第三種姿態。Mistral AI在官方公告「Introducing Forge」(https://mistral.ai/news/forge)中提出讓企業建立以自身專有知識為基礎的前沿級AI模型,並在其產品頁面強調企業資料隱私、部署控制與完整所有權。這反映出歐洲市場長期重視資料主權與合規性的需求。對許多金融、製造、公共部門與受監管產業而言,最強模型未必永遠是唯一答案;能否在本地、私有雲或受控環境中部署,能否讓資料不離開企業邊界,可能同樣重要。
GPT-5.5若如OpenAI所描述般能穩定完成模糊、多步驟、跨工具任務,最先受到衝擊的會是軟體開發與知識工作。程式碼代理已開始改變工程團隊的分工:初階實作、重構、測試、錯誤修復與文件生成,將更多由AI先行處理;人類工程師則需要把時間移向架構判斷、需求取捨、資安審查與最終責任。這不表示工程師會被簡單取代,而是工作內容被重新分層。能指揮AI代理、驗證輸出並整合進組織流程的人,價值可能上升;只依賴單一可複製技能的人,價格壓力會增加。
在顧問、法律、財務、研究與營運領域,影響也類似。AI可以把資料蒐集、初步分析、草稿生成與格式整理的時間壓縮,進而改變專業服務的計費邏輯。過去按工時累積的工作,可能被客戶要求轉向按成果、速度或風險承擔計價。這會使大型顧問公司、律所、投行與企業內部幕僚部門面臨相同問題:若AI能完成更多基礎工作,組織究竟需要多少初階人力來培養未來的資深人才?這是AI代理時代尚未解決的管理難題。
然而,GPT-5.5的前景不應被理解為無摩擦的自動化。代理式AI最大的挑戰,不是一次答錯,而是在長任務中以看似合理的方式逐步偏離目標。當模型可以操作工具、修改文件、發送請求或改動程式碼時,小錯誤可能被放大成流程錯誤。企業採用GPT-5.5,真正成本不只包括API價格,也包括權限設計、資料治理、稽核紀錄、人工覆核、錯誤回復與員工培訓。
此外,基準測試與實務場景之間仍有距離。OpenAI公布的數據顯示GPT-5.5在多項任務上領先或接近競爭者,但不同模型在不同任務上各有強弱。例如在OpenAI列出的SWE-Bench Pro公開數據中,Claude Opus 4.7仍高於GPT-5.5;在某些研究或金融任務上,Pro版本、競爭模型與工具設定也可能影響結果。企業採購不會只看單一榜單,而會看模型在自家資料、自家流程與自家風險限制下是否穩定。
GPT-5.5的發布,把AI產業帶入更現實也更複雜的階段。模型能力仍重要,但真正的競爭將越來越取決於制度能力:誰能提供更穩定的代理框架,誰能與企業資料安全地連接,誰能在成本與延遲上支撐大規模日常使用,誰能讓政府與受監管產業接受模型參與高風險工作。OpenAI憑藉ChatGPT、Codex與API取得先發位置;Anthropic以安全與長任務能力競爭;Google倚靠Workspace、雲端與搜尋生態;DeepSeek與中國廠商則以開源與成本壓力挑戰封閉模型;Mistral代表的歐洲路線則把主權、可控部署與企業資料邊界推到前台。
這次GPT-5.5的產業意義,並不在於它是否終結了模型競賽,而在於它把問題重新定義了。未來的AI產品不會只被問「它知道什麼」,而會被問「它能替組織完成什麼、在什麼限制下完成、出錯時誰負責」。當AI開始像同事一樣操作電腦,科技公司販售的就不只是智慧,而是一套新的工作秩序。GPT-5.5讓這個秩序更近一步成形,但它也提醒市場:真正困難的部分,未必是讓模型變得更聰明,而是讓組織學會在速度、信任與責任之間重新分配權力。
GPT-5.5看似是一場技術發布,實際上更像是一次企業制度的壓力測試。當模型能理解模糊指令、調用工作工具、撰寫程式、整理研究並生成可交付成果,企業採用AI的問題便從「要不要使用」轉成「哪些流程可以交給AI、哪些環節必須有人負責、哪些資料永遠不能離開控制邊界」。這些問題不會隨著模型分數提高而自動消失,反而會因模型能力提升而變得更急迫。
從市場角度看,OpenAI正試圖把GPT-5.5塑造成高階知識工作與企業代理任務的標準入口。這條路若成功,ChatGPT將不只是應用程式,而可能成為新一代工作介面;Codex也不只是程式助理,而可能成為軟體開發流程中的常駐成員。可是,競爭者不會停在原地。Anthropic會繼續以安全與長任務能力爭取企業信任,Google會以雲端、Workspace與搜尋生態推動AI滲透,中國模型會用開源與成本效率擠壓價格,歐洲業者則會把資料主權與可控部署變成差異化賣點。
因此,GPT-5.5的真正考驗不在發布日,而在接下來數月到數年的企業採用曲線。它若能穩定減少重複性工作、降低錯誤率、縮短開發與研究週期,將推動AI從輔助工具走向組織基礎設施;若它在可靠性、治理與責任歸屬上仍頻繁碰壁,市場便會再次提醒矽谷,智慧本身並不等於生產力。這也是這場競賽最值得觀察之處:AI模型愈像員工,企業就愈需要像管理員工一樣管理它。

留下你的姓名與電郵,我們會在後續整理實用文章與產品觀點時通知你。


過去三個月,Pimker 針對 AI 引用做咗一輪三階段研究:320 個網站、50 個行業,累計超過 3,330 次 citation...
閱讀文章




新網站剛剛上線,好多公司都會以為「網站做好咗,客戶應該慢慢會嚟」。但實際情況好多時係:Google 搵唔到...
閱讀文章

會,通常會有幫助。即使你只用 mini 方案優化首頁,只要首頁喺 AI 搜尋、ChatGPT、Gemini、Claude 等 LLM...
閱讀文章

H 輪融資令 Anthropic 由模型公司變成基建級 AI 玩家 Anthropic 於 2026 年 5 月 28 日公布最新 H 輪融資,...
閱讀文章
好多小老闆、自僱人士同獨立品牌經營者,而家都已經開始用 AI 內容生成工具。由 blog 文章、社交平台帖文、...
閱讀文章
2026年5月中旬,Anthropic把Claude的商業化敘事從「模型能力」推向更具體的「工作流執行」。公司一方面推出...
閱讀文章
© Pimker 好評家 2026 企業首選 AI 市場推廣軟件 All rights reserved.