Claude Opus 4.7 來了:開發與資安能力大幅強化
【 AI 新聞 | 編輯:Sandy】 Anthropic於2026年4月16日正式推出Claude Opus 4.7,並同步在Claude產品線、開發者API,以及Amazon Bedrock、Google Cloud Vertex AI與Micros
【 AI 新聞 | 編輯:Sandy】 Anthropic於2026年4月16日正式推出Claude Opus 4.7,並同步在Claude產品線、開發者API,以及Amazon Bedrock、Google Cloud Vertex AI與Micros

【 AI 新聞 | 編輯:Sandy】
Anthropic於2026年4月16日正式推出Claude Opus 4.7,並同步在Claude產品線、開發者API,以及Amazon Bedrock、Google Cloud Vertex AI與Microsoft Foundry等平台全面開放。這次更新的關鍵不只在於模型變得更會寫程式,而在於Anthropic明確把競爭焦點推向更高價值的「長時間複雜任務」:讓模型不只是回答問題,而是能在較少監督下,持續規劃、執行、檢查並修正自己的工作流程。更值得注意的是,Anthropic也首次在這一代模型上實際部署新的資安偵測與阻擋機制,讓Opus 4.7成為其下一代安全治理策略的第一個真實試驗場。
根據Anthropic官方公告〈Introducing Claude Opus 4.7〉(https://www.anthropic.com/news/claude-opus-4-7),Opus 4.7最大的進步集中在進階軟體工程任務,尤其是那些需要長時間推進、跨多步驟判斷與持續驗證的工作。官方對外傳達的訊息相當明確:過去必須緊盯模型、隨時糾錯的高難度程式任務,現在開始可以更放心地交給模型自主完成。這種說法若放在一年前,仍可能像是典型的行銷措辭;但放在2026年的生成式AI競爭格局裡,卻有更清楚的商業含義。
原因在於,市場已逐漸從「誰更會對話」轉向「誰更能完成工作」。企業客戶真正願意付費的,不是模型能否寫出一段漂亮範例碼,而是能否在真實軟體流程中處理除錯、測試、規格理解、文件整理、工具調用、異常恢復與長上下文追蹤。Anthropic此次強調Opus 4.7在最困難類型任務上進步最明顯,等於是在告訴市場:Claude的下一個主戰場,不再只是通用聊天機器人,而是企業工程部門與代理型工作流。
這一點也解釋了為何Anthropic維持與前代相同的API定價,仍為每百萬輸入token 5美元、輸出token 25美元。當能力上升而價格不變,訊號很清楚:公司想搶的不是零星個人用戶,而是高頻率、可規模化導入的開發與企業工作流預算。與其說這是一次模型更新,不如說是Anthropic對企業採購部門發出的價格與效能雙重訊號。
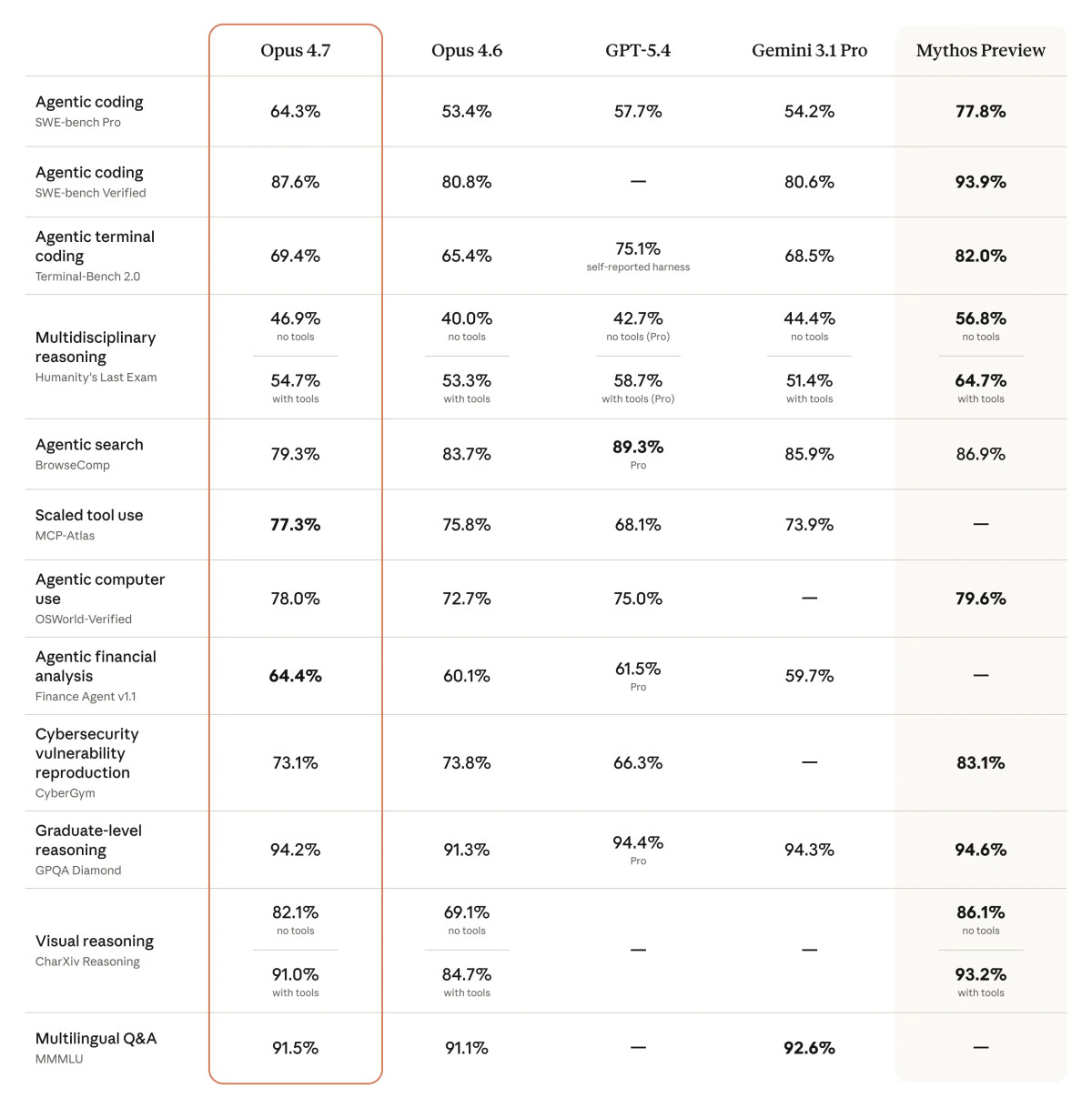
從Anthropic公布的早期測試結果來看,Opus 4.7的提升不是停留在實驗室基準,而是刻意用接近生產環境的任務來說服市場。官方引述Cursor共同創辦人的說法指出,在其內部評測中,Opus 4.7通過70%的任務,而Opus 4.6為58%。Rakuten則表示,在其內部軟體工程評測中,Opus 4.7解決實際生產任務的比例是前代三倍,且程式碼品質與測試品質都有雙位數成長。Harvey的BigLaw Bench測試則顯示,這一版本在高精力模式下達到90.9%的準確率,並在過去前沿模型容易混淆的法律條款辨識任務上表現出色。
這組訊號很關鍵。首先,它說明模型的能力評估正在從單次問答或基準分數,轉向「是否能被部署進真實流程」。其次,它也反映AI編碼工具的商業形態正在改變。第一階段的工具是協助工程師補全、重構、查錯;第二階段則是代理人化,讓模型能連續處理多個子任務,甚至在工具失敗時自行修補流程。Anthropic在公告中強調Opus 4.7會「在回報前驗證自己的輸出」,這其實是代理型AI能否走進企業現場的核心門檻之一。若模型無法檢查自己,它就只能是華麗但不可靠的助手;若模型能做自我驗證,它才可能成為被交辦任務的執行者。
若只把Opus 4.7視為更強的寫程式模型,反而低估了這次升級的真正方向。Anthropic表示,模型現在可接受最長邊2,576像素的圖片,解析度較前代提高逾三倍。這個規格本身或許不像基準分數那樣耀眼,但其產業意義不容小覷。
對電腦操作代理人而言,畫面理解的精度直接決定可用性。當AI需要閱讀儀表板、辨認複雜介面、從圖表中擷取數據、或在密集UI上點選與比對內容時,模型是否能準確看清楚像素細節,往往比純文字推理更實際。Anthropic此次點名computer-use agent、高密度畫面理解、複雜圖表擷取與生命科學圖像判讀,等於是在暗示Claude的下一步不是只有「產出內容」,而是「操作數位環境」。在企業軟體世界裡,能讀懂畫面與操作介面的模型,比只會輸出文字的模型更接近真正可替代部分知識工作的人機協作單位。
這也使Anthropic與OpenAI、Google之間的競賽更進一步收斂。OpenAI在〈Codex for (almost) everything〉(https://openai.com/index/codex-for-almost-everything/)中提到,Codex更新後已可在使用者電腦旁並行操作,還能調用更多工具、操作桌面應用、生成圖片、記憶偏好並承接重複性工作。Google則在Vertex AI文件〈Gemini 2.5 Pro〉(https://docs.cloud.google.com/vertex-ai/generative-ai/docs/models/gemini/2-5-pro)中強調,Gemini 2.5 Pro可處理文字、程式碼、影像、音訊、影片甚至整個程式碼庫。三家公司走向其實相當一致:AI模型的競爭標準,已從語言品質轉向多模態理解、長上下文處理、工具使用與持續執行能力。
真正讓Opus 4.7顯得不同的,不只是性能,而是它承載了Anthropic更大的安全戰略。公告指出,Anthropic上週才剛對外介紹Project Glasswing,而Opus 4.7正是第一個部署新資安防護策略的模型。根據Anthropic官方頁面〈Project Glasswing〉(https://www.anthropic.com/project/glasswing),這項計畫由Amazon Web Services、Apple、Cisco、CrowdStrike、Google、JPMorganChase、Microsoft、NVIDIA與Palo Alto Networks等機構參與,目的在於利用前沿AI協助保護全球關鍵軟體基礎設施,Anthropic也承諾提供高額使用額度與資源支持。
Opus 4.7的角色因此非常清楚:它不是最強的那個模型,卻是最先被放進實際安全治理體系裡測試的模型。Anthropic公開表示,這套機制會自動偵測並阻擋顯示為禁止或高風險資安用途的請求,同時又開放合法的資安研究人員透過Cyber Verification Program取得使用資格。這種分流設計透露出兩層策略。第一,Anthropic希望在「能做更多」與「不能被濫用」之間建立一套可商業化、可審計的中介機制。第二,它也在為未來更高能力的Mythos級模型鋪路,先用能力稍低但已足夠強大的Opus 4.7做真實世界壓力測試。
這與OpenAI在〈Introducing GPT-5.3-Codex〉(https://openai.com/index/introducing-gpt-5-3-codex/)中談到的「Securing the cyber frontier」形成耐人尋味的對照。OpenAI同樣把更強的代理型編碼模型與資安能力放在一起討論,甚至列出其在網路安全攻防挑戰上的表現。這意味著美國領先AI公司已經不再把安全當成產品外部約束,而是把安全治理本身做成產品路線的一部分。未來比的不只是模型有多強,而是公司能否證明自己能在高能力模型上做出可運行的控管機制。
若從國際視角來看,Anthropic這次發表正好落在全球AI競賽重新分流的時刻。美國公司目前明顯押注封閉但高度整合的企業級代理模式。Anthropic、OpenAI與Google都在加強模型、工具、雲端平台與企業部署能力的整合,並試圖把AI從單點能力擴大為可嵌入企業作業系統的基礎層。
中國公司的路徑則更偏向快速擴散與成本效率。阿里雲在〈Qwen3.6-Plus: Towards Real World Agents〉(https://www.alibabacloud.com/blog/qwen3-6-plus-towards-real-world-agents_603005)中強調,Qwen3.6-Plus將推理、記憶與執行能力深度整合,主打編碼代理、一般代理與工具使用的全面提升,並標榜1M上下文與更強的多模態能力。這類產品策略反映中國市場對「高可用、可擴散、成本敏感」的偏好,也意味著競爭不一定只比最頂尖封閉模型,而是比誰能更快滲透更多開發者與企業場景。
歐洲則走出另一條路。法國Mistral AI在〈Introducing: Devstral 2 and Mistral Vibe CLI.〉(https://mistral.ai/news/devstral-2-vibe-cli)中推出開源導向的Devstral 2與命令列代理工具,強調開放授權、較低部署門檻、可本地運行,以及對企業內部環境的可控性。這條路線雖然短期內未必在封閉前沿能力上領先美國,但在主權AI、隱私、在地部署與法規合規上,對歐洲與受監管產業具有不小吸引力。
換言之,Anthropic的Opus 4.7並不是在一個真空市場裡競爭。美國代表整合式封閉前沿平台,中國代表高效率擴散式部署,歐洲則代表開源與主權控制。未來三到五年,這三條路線可能同時存在,且會在不同產業與地區各自找到優勢。
Anthropic此次也特別強調Opus 4.7並非只存在於Claude自家介面,而是同步上架Amazon Bedrock、Google Cloud Vertex AI與Microsoft Foundry。這看似只是通路資訊,實際上卻透露極強烈的戰略意圖:Anthropic想成為跨雲平台都不可忽視的模型供應商。
在生成式AI的企業市場裡,模型本身固然重要,但更重要的是是否能被無縫納入既有雲端架構、資安規範、權限治理與採購流程。只要能在三大雲端平台同時上架,Anthropic就不必完全依賴自家前台產品吸引用戶,而能直接進入企業已經存在的IT採購與部署體系。這種做法也與Google、OpenAI及Microsoft的策略形成交錯競合:一方面,Anthropic要借力雲端巨頭的企業渠道;另一方面,它也在這些巨頭的地盤上,直接與它們自家的模型產品競爭。
這是當前AI產業最值得注意的結構性變化之一。模型公司不再只是API供應商,而正在試圖成為企業軟體堆疊中的核心依賴層。誰能穩定進入雲端市場、獲得企業安全認證、證明成本與效能可預測,誰就更可能在市場洗牌後留在主桌。
Opus 4.7的影響,不會只停留在工程師是否更省時間,而是可能改變企業如何計算人力、軟體交付與知識工作成本。當模型能獨立處理更多高難度任務,企業未來衡量AI價值的方式,將從「節省多少查資料時間」轉為「減少多少人工審核、測試與反覆交辦」。若模型在長時間任務中的穩定性持續提升,產品經理、法務、研究人員與分析師的工作流也會加速代理化。
這也說明為何Anthropic這次不只強調編碼,還突出文件、簡報、介面設計與圖表理解能力。企業採購者想要的從來不是單一功能,而是一種可跨部門複用的高價值能力。如果Opus 4.7真的如測試者所稱,在資料缺漏時更誠實、在工具失敗時能自我修復、在複雜任務中更少中斷,那麼它賣的就不是模型,而是更可靠的企業執行單元。
不過,限制也同樣明顯。首先,早期測試結果多由合作夥伴或官方挑選案例提供,外界仍需更多公開、可重現的第三方評測來驗證其在不同程式語言、不同工具鏈與不同產業流程中的表現。其次,模型越能自主執行,企業對審計、權限控制、資料隔離與責任歸屬的要求就會越高。再者,當市場上同時存在Anthropic、OpenAI、Google、阿里雲與Mistral等多條技術路線時,企業很可能不會單押單一供應商,而會採取多模型與多雲並行策略,這也壓縮了任何一家公司建立絕對護城河的空間。
從短期看,Claude Opus 4.7是一個更強的編碼與長任務模型;從中期看,它是Anthropic把安全策略、雲端分發與企業代理工作流綁在一起的關鍵節點;從更長期看,它則像是一場更大實驗的前哨戰:當AI模型開始具備更高自主性,產業究竟會接受什麼樣的安全閾值、商業模式與部署規範。
若Anthropic能證明,模型能力提升不必以安全鬆綁為代價,且跨雲平台部署能與企業治理共存,那麼它在下一階段競爭中的優勢,可能不只是「模型表現更好」,而是「更容易被大企業採用」。但若市場最終更在意成本、開放性或本地部署能力,來自中國與歐洲的競爭者也未必沒有機會從另一側打開局面。
因此,Opus 4.7的意義不只在於它今天做到了什麼,而在於它透露出整個產業正在往哪裡走:從聊天機器人走向代理型工作系統,從模型競賽走向治理競賽,從單點工具走向企業基礎設施。這場競爭的勝負,或許不會只由基準分數決定,而會由誰最先把「強大、可控、可部署」三件事同時做成現實來決定。
留下您的姓名與 Email,我們會在後續整理實用文章與產品觀點時通知您。
【 AI 軟體介紹 | 編輯:Sandy】 Flux AI 是一個把 AI 圖像生成、圖像編輯與影片生成整合在同一平台上的創...
閱讀文章
【 AI 優化 | 編輯:Adda Lin】 AI Overviews 不是新功能而已,而是搜尋結果的敘事方式變了 AI Overviews...
閱讀文章
【AI 新聞 | 編輯:Sandy】 Anthropic 最新推出的 Claude Code Routines,把 AI 編碼工具從「有人在場才會...
閱讀文章
【 AI 新聞 | 編輯:Sandy】 Google 再次把人工智慧往更貼近日常操作的一步推進。根據 Google 官方部落格...
閱讀文章
客戶背景 本案例為一間提供多元牙科服務的牙醫診所,已具備基本數位基礎,包括官方網站與 Google Maps 商家...
閱讀文章
【 AI 新聞 | 編輯:Sandy】 Google最新釋出的Gemini for Mac,表面上是一款獨立的macOS應用程式,實際上...
閱讀文章


【AI 新聞 | 編輯:Sandy】 OpenAI在2026年3月31日拋出一則分量極重的官方公告:公司已完成最新一輪融資,...
閱讀文章
【 ChatGPT應用 | 編輯:Jason Chen】 當企業開始導入生成式 AI,第一個常見卡關點通常不是模型選擇,而是...
閱讀文章
【AI 新聞 | 編輯:Sandy】 Anthropic於2026年4月8日發布「Claude Managed Agents」,這不只是一次例行產...
閱讀文章
【觀點/深度分析 | 編輯:Sandy】 當生成式人工智慧從「會回答問題」進一步走向「能代替人執行任務」,資...
閱讀文章
【 AI 最新消息 | 編輯:Sandy】 在2026年4月最新發布中[ https://ai.meta.com/blog/introducing-muse-spa...
閱讀文章
【 ChatGPT應用 | 編輯:Jason Chen】 在社群媒體當道的時代,Facebook(FB)早已成為品牌經營、個人分享...
閱讀文章
【 AI 軟體介紹 | 編輯:Sandy】 在內容創作越來越講求「氛圍感」的時代,Vibepicture 主打把抽象的情緒與...
閱讀文章© Pimker 好評家 2026 企業首選 AI 行銷軟件 All rights reserved.