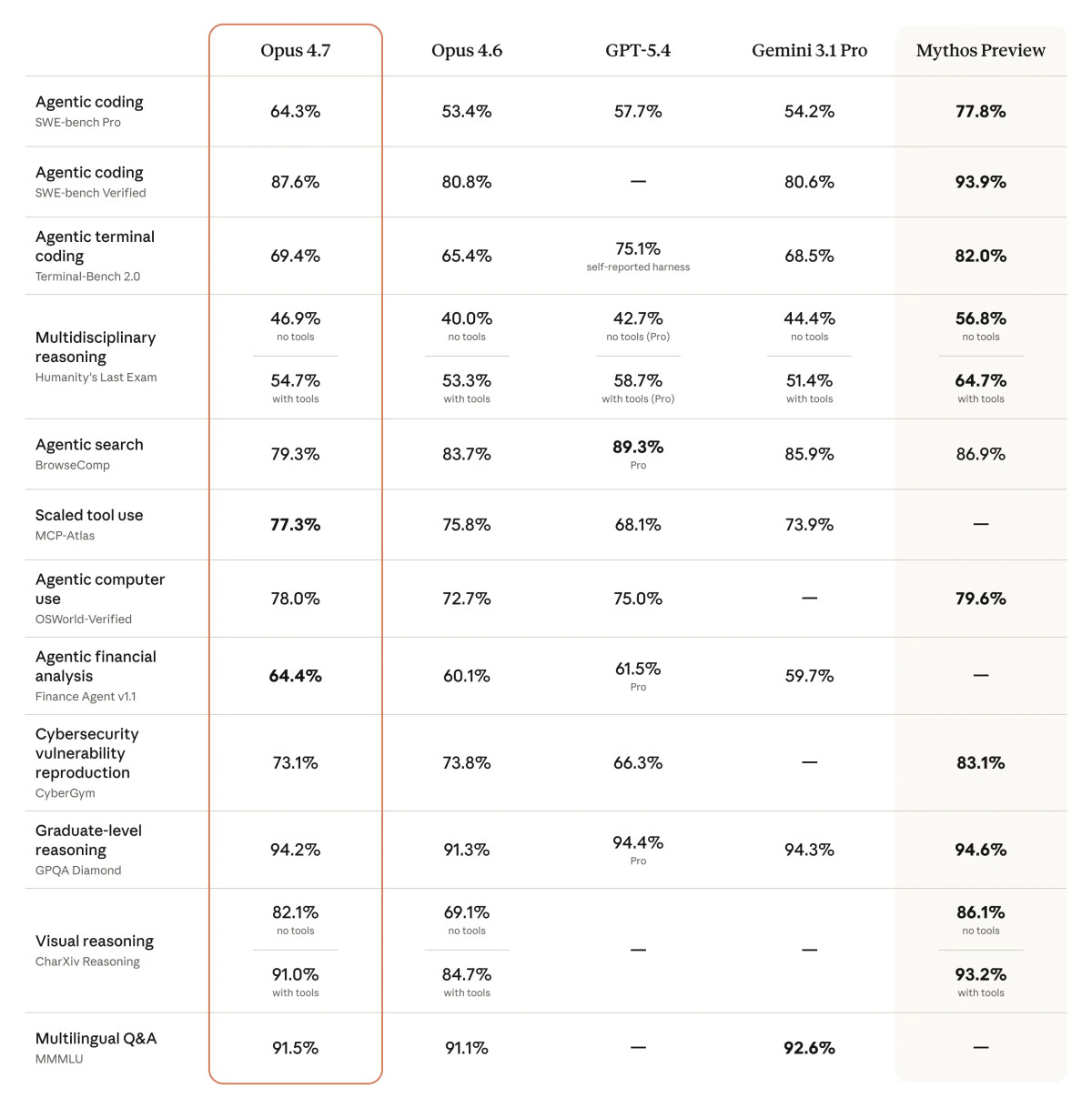
Claude Opus 4.7 Is Here: Major Upgrades to Development and Security Capabilities
AI News | Editor: Sandy On April 16th 2026 Anthropic officially unveiled Claude Opus 4.7 and made it broadly available across the Claude product suite, the deve
AI News | Editor: Sandy On April 16th 2026 Anthropic officially unveiled Claude Opus 4.7 and made it broadly available across the Claude product suite, the deve

AI News | Editor: Sandy
On April 16th 2026 Anthropic officially unveiled Claude Opus 4.7 and made it broadly available across the Claude product suite, the developer API, and major cloud platforms including Amazon Bedrock, Google Cloud Vertex AI and Microsoft Foundry. The significance of the release lies not merely in better coding performance, but in a sharper strategic shift towards high-value, long-duration and complex tasks: Anthropic is positioning the model not simply as something that answers questions, but as a system that can plan, execute, verify and revise work over sustained periods with less supervision. Just as notably, the company has used this version to deploy a new cybersecurity detection and blocking mechanism for the first time, turning Opus 4.7 into the first live testing ground for Anthropic’s next-generation model safety strategy.
According to Anthropic’s official announcement, “Introducing Claude Opus 4.7” (https://www.anthropic.com/news/claude-opus-4-7), the model’s largest gains are concentrated in advanced software-engineering tasks, especially those that require sustained execution, multi-step judgement and ongoing verification. The message Anthropic is sending to the market is unusually clear: high-difficulty coding work that previously demanded close human supervision can now be delegated more confidently to the model. A year ago, such a claim might have sounded like polished marketing. In 2026, in the middle of a fierce contest over generative AI, it carries a more concrete commercial meaning.
That is because the market is moving away from a simple question of who can converse most fluently towards a harder and more valuable one: who can actually complete useful work. Enterprise customers do not pay serious money for a model that can produce elegant sample code in isolation. They pay for systems that can debug, test, interpret specifications, organise documentation, call tools, recover from failure and track long chains of context inside real software workflows. By stressing that Opus 4.7 shows its biggest improvements on the most difficult tasks, Anthropic is effectively telling customers that Claude’s next battleground is no longer just the chatbot interface. It is the engineering department, and the broader world of agentic enterprise workflows.
That also helps explain why Anthropic has kept API pricing unchanged from the previous generation, at $5 per million input tokens and $25 per million output tokens. If capability rises while price remains flat, the signal is unmistakable: the firm is not chasing sporadic consumer use, but recurrent and scalable enterprise spending on development workflows. This is not just a model update. It is a performance-and-pricing message aimed squarely at procurement teams.
Anthropic’s early testing examples suggest that Opus 4.7’s progress is meant to resonate beyond laboratory benchmarks. The company deliberately leans on evaluations that look closer to real production work. It cites Cursor’s co-founder as saying that the model passed 70% of tasks in the company’s internal benchmark, compared with 58% for Opus 4.6. Rakuten says that in its internal software-engineering evaluation, Opus 4.7 solved real production tasks at three times the rate of the earlier version, while both code quality and testing quality improved by double digits. Harvey’s BigLaw Bench testing, meanwhile, showed 90.9% accuracy in high-effort mode, with notably stronger performance on contract-clause identification tasks where frontier models have often stumbled.
These signals matter for two reasons. First, they suggest that AI capability assessment is shifting away from one-shot question answering or headline benchmark scores towards a tougher question: can the model be embedded inside a real workflow? Secondly, they reflect a broader change in the business form of AI coding tools. The first wave helped engineers autocomplete, refactor and troubleshoot. The second wave is more agentic: models are expected to handle multiple linked subtasks in sequence and even repair the workflow when tools fail. Anthropic’s emphasis that Opus 4.7 verifies its own outputs before reporting back points to one of the central thresholds for agentic AI in the enterprise. A model that cannot check its own work remains a polished assistant. A model that can validate itself begins to look like an executor that can be trusted with a task.
To see Opus 4.7 merely as a stronger coding model would be to underrate the direction of the release. Anthropic says the model can now accept images with a longest edge of 2,576 pixels, more than tripling the resolution supported by the previous version. That may not sound as dramatic as a benchmark score, but its industrial significance is substantial.
For computer-use agents, visual precision is not a decorative feature; it is a practical requirement. When an AI system needs to read dashboards, recognise dense interfaces, extract information from charts, or click and compare content in crowded user interfaces, the ability to perceive pixel-level detail often matters more than elegant textual reasoning. By explicitly highlighting computer-use agents, dense-screen reading, complex chart extraction and scientific image interpretation, Anthropic is signalling that Claude’s trajectory extends beyond content generation towards operating inside digital environments. In enterprise software, a model that can see and navigate interfaces is far closer to becoming a genuine unit of human-machine collaboration than one that can only emit text.
That also tightens the competitive convergence between Anthropic, OpenAI and Google. In “Codex for (almost) everything” (https://openai.com/index/codex-for-almost-everything/), OpenAI describes an updated Codex that can work in parallel alongside the user, call more tools, operate desktop applications, generate images, remember preferences and take over repetitive work. Google, in its Vertex AI documentation for “Gemini 2.5 Pro” (https://docs.cloud.google.com/vertex-ai/generative-ai/docs/models/gemini/2-5-pro), stresses that Gemini 2.5 Pro can process text, code, images, audio, video and even entire code repositories. The direction of travel is strikingly similar across all three firms. The standard of competition has moved beyond fluency in language towards multimodal understanding, long-context handling, tool use and sustained execution.
What truly distinguishes Opus 4.7 is not only performance, but the larger safety strategy it now carries. Anthropic notes that it introduced Project Glasswing only a week earlier, and that Opus 4.7 is the first model on which its new cyber-defence strategy has been deployed. According to Anthropic’s “Project Glasswing” page (https://www.anthropic.com/project/glasswing), the initiative brings together organisations including Amazon Web Services, Apple, Cisco, CrowdStrike, Google, JPMorganChase, Microsoft, NVIDIA and Palo Alto Networks to use frontier AI to help protect critical software infrastructure, with Anthropic pledging significant access credits and resources.
Opus 4.7’s role is therefore unusually revealing. It is not simply the company’s latest powerful model; it is the first one placed inside a live safety architecture for real-world testing. Anthropic says the system is designed to automatically detect and block requests that appear to involve prohibited or high-risk cyber abuse, while still allowing legitimate security researchers to gain access through its Cyber Verification Program. That split-screen approach reveals two strategic aims. First, Anthropic wants a commercially usable middle layer between “models that can do more” and “models that can be abused more easily”. Secondly, it appears to be preparing the ground for even more capable future systems, using Opus 4.7 as a real-world pressure test before stronger model classes arrive.
That makes for an intriguing comparison with OpenAI’s “Introducing GPT-5.3-Codex” (https://openai.com/index/introducing-gpt-5-3-codex/), which also links more capable agentic coding systems with cybersecurity concerns and details performance on cyber challenges. America’s leading AI firms are no longer treating safety as an external compliance burden. They are building governance directly into the product roadmap. The next contest will not be decided only by which model is more capable, but by which company can show that powerful systems can be governed in a way that actually works in production.
From an international perspective, Anthropic’s launch arrives at a moment when global AI competition is beginning to split into distinct strategic routes. American firms are clearly leaning towards closed but tightly integrated enterprise-grade agent systems. Anthropic, OpenAI and Google are all reinforcing the integration between models, tools, cloud platforms and enterprise deployment, trying to turn AI from a standalone capability into a foundational layer embedded inside corporate operations.
Chinese firms, by contrast, are often pushing harder on rapid diffusion and cost efficiency. In “Qwen3.6-Plus: Towards Real World Agents” (https://www.alibabacloud.com/blog/qwen3-6-plus-towards-real-world-agents_603005), Alibaba Cloud presents Qwen3.6-Plus as a system that tightly combines reasoning, memory and execution, with major improvements in coding agents, general agents and tool use, alongside a one-million-token context window and stronger multimodal capability. That product logic reflects the priorities of a market that is highly sensitive to cost, speed of adoption and deployment at scale. In such a market, competition is not only about who has the single best frontier model, but also about who can spread usable capability fastest across developers and businesses.
Europe is charting a different course again. France’s Mistral AI, in “Introducing: Devstral 2 and Mistral Vibe CLI.” (https://mistral.ai/news/devstral-2-vibe-cli), has introduced open-oriented coding tools that emphasise open licensing, lower deployment barriers, local operation and stronger enterprise control inside internal environments. That approach may not immediately outgun the top closed American models on frontier performance, but it has real appeal in markets where sovereignty, privacy, local deployment and regulatory compliance matter deeply.
In other words, Opus 4.7 is not competing in a vacuum. America represents the integrated closed frontier platform; China represents rapid, cost-efficient diffusion; Europe represents openness and sovereign control. Over the next three to five years, those three approaches may well coexist, each finding its advantage in different sectors and regions.
Anthropic also goes out of its way to stress that Opus 4.7 does not live only inside the Claude interface. It is simultaneously available through Amazon Bedrock, Google Cloud Vertex AI and Microsoft Foundry. That may sound like routine distribution news. In fact, it reveals a strong strategic ambition: Anthropic wants to become a model supplier that enterprises cannot ignore, regardless of which cloud they use.
In the enterprise generative-AI market, the model itself matters, but the larger question is whether it can be absorbed smoothly into existing cloud architecture, security controls, governance frameworks and procurement systems. Once a model appears across the three biggest cloud ecosystems, the vendor no longer relies solely on its own front-end product to win customers. It can enter enterprise IT stacks through channels that already exist. This also creates a curious competitive overlap with the hyperscalers themselves. Anthropic is using the cloud giants’ distribution power while simultaneously competing on their own territory against their in-house AI offerings.
This is one of the most important structural shifts in the AI industry today. Model companies are no longer merely API providers. They are trying to become indispensable layers in enterprise software stacks. Those that can establish themselves inside cloud marketplaces, satisfy security expectations and deliver predictable cost-performance trade-offs are more likely to remain at the main table once the market starts to consolidate.
The effect of Opus 4.7 will not be limited to whether engineers save some time. More important is the possibility that it changes how firms calculate labour, software delivery and the cost of knowledge work. As models become capable of handling more difficult tasks independently, businesses will shift from measuring AI by how much time it saves on searching or drafting towards how much human review, testing and repeated delegation it can remove from the process. If stability in long-duration tasks continues to improve, the same agentic logic will spread beyond engineering to product managers, legal teams, researchers and analysts.
That helps explain why Anthropic is not speaking only about coding, but also about document work, slide generation, interface design and chart understanding. What enterprise buyers want is rarely a narrow feature. They want a high-value capability that can be reused across departments. If Opus 4.7 really is, as early users suggest, more honest when information is missing, better at self-repair when tools fail, and less likely to lose its footing on complex tasks, then Anthropic is no longer selling only a model. It is selling a more dependable execution layer for enterprise work.
Yet the constraints are just as real. Early testing results still come largely from partners and selected examples, so wider public and reproducible third-party evaluation will be needed to establish how robust the model is across languages, toolchains and industries. As models become more autonomous, demands for auditability, permission control, data isolation and accountability will rise sharply. And with Anthropic, OpenAI, Google, Alibaba Cloud and Mistral all pursuing different technical and commercial paths, many enterprises will choose not to rely on a single supplier at all. A multi-model, multi-cloud strategy may become the default, limiting any one firm’s ability to build an impregnable moat.
In the short run, Claude Opus 4.7 is a stronger model for coding and long-duration complex tasks. In the medium term, it is a crucial node in Anthropic’s attempt to bind together safety strategy, cloud distribution and enterprise agent workflows. In the longer run, it looks like the advance guard of a larger experiment: as AI models gain more autonomy, what level of safety, governance and deployment discipline will the market ultimately accept?
If Anthropic can prove that stronger model capability does not have to come at the price of looser safety controls, and that cross-cloud deployment can coexist with enterprise governance, then its advantage in the next stage of competition may rest not only on better model performance, but on being easier for big organisations to adopt. But if the market ends up caring more about cost, openness or local deployment, then competitors from China and Europe may still open up other fronts of their own.
That is why the significance of Opus 4.7 lies not only in what it does today, but in what it reveals about where the industry is heading: from chatbots to agentic work systems, from model rivalry to governance rivalry, and from single-purpose tools to enterprise infrastructure. The outcome of that contest may be decided less by benchmark scores than by who can first make three things real at the same time: power, control and deployability.
Leave your name and email to receive future updates from our blog and product insights.
AI Software | Editor: Sandy In a world where visual storytelling is increasingly driven by “vibes,”...
Read Article
ChatGPT Applications | Edited by Jason Chen In the age of social media dominance, Facebook (FB) has...
Read Article
AI News | Editor: Sandy In its latest announcement in April 2026 ( https://ai.meta.com/blog/introduc...
Read Article
Opinion / In-depth Analysis | Editor: Sandy As generative artificial intelligence evolves from answe...
Read Article
AI News | Editor: Sandy On April 8, 2026, Anthropic unveiled “Claude Managed Agents,” a release that...
Read Article
ChatGPT Applications | Edited by Jason Chen When organizations begin adopting generative AI, the fir...
Read Article
AI News | Editor: Sandy On March 31st 2026 OpenAI published an announcement of unusual weight: the c...
Read Article
AI News | Editor: Sandy The latest development surrounding Anthropic is not merely a product update....
Read Article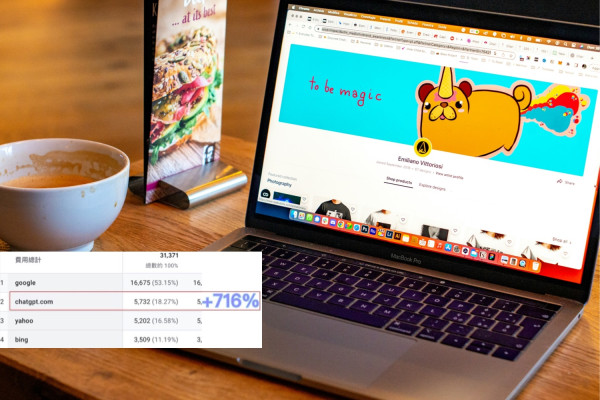
In today’s increasingly competitive pet food market, many e-commerce brands face the same challenge:...
Read Article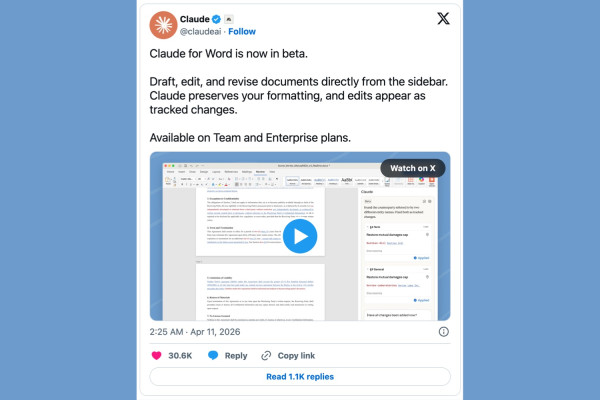
AI News | Editor: Sandy On April 10, Anthropic launched the beta version of “Claude for Word”, embed...
Read Article
AI Software | Editor: Sandy Flux AI is an all-in-one platform that combines AI image generation, ima...
Read Article
AEO | Editor: Adda Lin AI Overviews Are Not Just a New Feature. They Change the Narrative Structure...
Read Article
AI News | Editor: Sandy Anthropic’s latest launch, Claude Code Routines, pushes AI coding tools from...
Read Article
AI News | Editor: Sandy Google has moved artificial intelligence one step closer to the everyday act...
Read Article
Background This case features a dental clinic offering a wide range of services. The clinic already...
Read ArticlePimker - The AI marketing platform built for businesses
© Pimker 2026 The AI marketing platform built for businesses All rights reserved.