GPT-5.5 Arrives: OpenAI Pushes the AI Race Into the Era of “Getting Things Done”
AI News | Editor: Sandy OpenAI released GPT-5.5 on April 23, 2026, and followed up on April 24 by announcing that GPT-5.5 and GPT-5.5 Pro were available through
AI News | Editor: Sandy OpenAI released GPT-5.5 on April 23, 2026, and followed up on April 24 by announcing that GPT-5.5 and GPT-5.5 Pro were available through
AI News | Editor: Sandy
OpenAI released GPT-5.5 on April 23, 2026, and followed up on April 24 by announcing that GPT-5.5 and GPT-5.5 Pro were available through the API. That makes this launch more than another model upgrade. It marks the latest stage in AI’s shift from “answering questions” to acting as an agent that can complete work. According to OpenAI’s official announcement, “Introducing GPT-5.5” (https://openai.com/index/introducing-gpt-5-5/), GPT-5.5 is designed for knowledge work, computer use, coding, and tool-based tasks. It is said to be better at understanding what users want and pushing tasks forward across tools, even when prompts are incomplete, multi-step, or ambiguous. The industrial implication is plain enough: the competition among large language models is moving away from single-turn cleverness and toward the more valuable question of which system can reliably complete complex tasks in real working environments.
The central positioning of GPT-5.5 is what OpenAI calls a new level of intelligence for real work. The model is not merely meant to generate text, organize information, or write snippets of code. It is designed to research material, analyze data, create documents and spreadsheets, operate software, and move between tools until the job is done. The distinction from earlier versions of ChatGPT is important. In the past, users often had to break a task into several pieces and prompt the model step by step. GPT-5.5 is presented as a system built for messier tasks that more closely resemble actual office work: gathering information, testing assumptions, and turning the result into a deliverable.
OpenAI’s announcement places particular emphasis on GPT-5.5’s value inside Codex and ChatGPT, especially in agentic coding, knowledge work, scientific research, and computer use. That represents a meaningful turn. AI companies once tried to persuade the market by showing whether models could pass math, science, or general knowledge benchmarks. But what enterprises actually pay for is often not whether a model can solve a difficult puzzle. It is whether the model can save time for engineers, analysts, lawyers, researchers, or finance teams. OpenAI’s internal examples tell the same story. The company says its finance team used Codex to review 24,771 K-1 tax forms, totaling 71,637 pages, and finished two weeks faster than the previous year; members of its go-to-market team reportedly saved five to ten hours a week by automating weekly reports. These examples may not generalize neatly to every enterprise setting, but they point to a clearer commercial proposition: AI is no longer just selling “answers.” It is selling workflow compression.
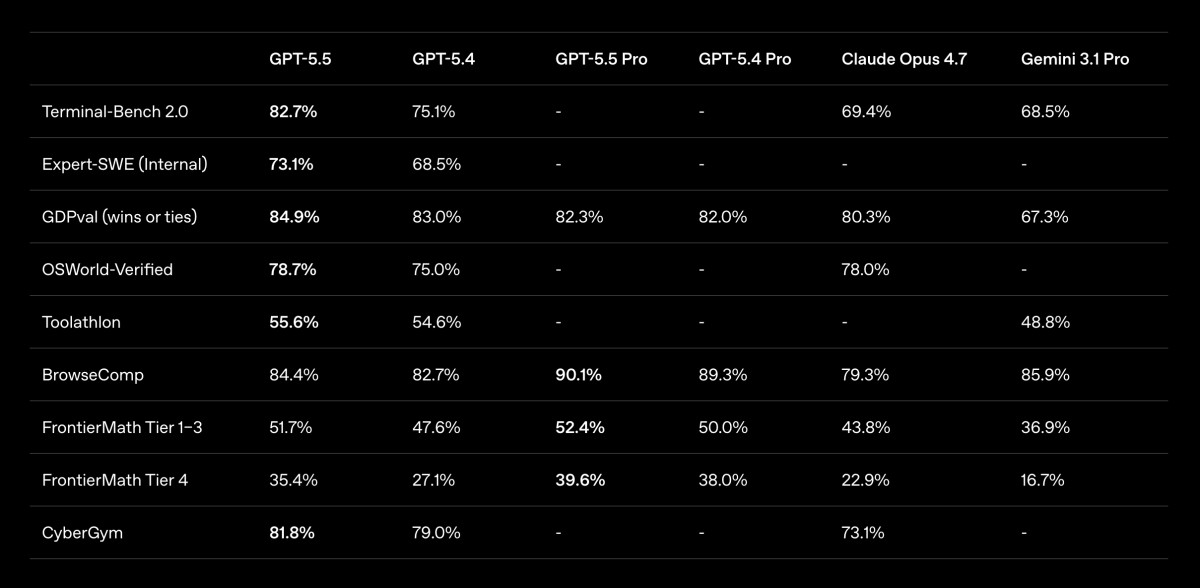
The technical story around GPT-5.5 has two layers. The first is capability. OpenAI says GPT-5.5 scores 82.7% on Terminal-Bench 2.0, 58.6% on SWE-Bench Pro, 78.7% on OSWorld-Verified, and 84.9% on GDPval. Such figures should be read with care, since benchmarks are shaped by datasets, evaluation methods, and their distance from real-world use. Still, they capture an important direction of travel: models are moving from “can answer” to “can operate” and “can sustain progress over time.” OSWorld-Verified is especially telling because it tests whether a model can autonomously operate in a real computer environment. That is much closer to the lived reality of enterprise software than pure text-based reasoning.
The second layer is cost and speed. OpenAI says GPT-5.5’s per-token latency in production can match GPT-5.4 while delivering higher intelligence, and that it completes Codex tasks with fewer tokens. That matters enormously for commercialization. If the capabilities of large models can only be obtained through more expensive and slower inference, they risk remaining impressive demonstrations rather than everyday business tools. If better capability comes with better inference efficiency, however, the model has a better chance of entering recurring daily workflows. OpenAI also says GPT-5.5 is priced in the API at $5 per million input tokens and $30 per million output tokens, while GPT-5.5 Pro costs $30 per million input tokens and $180 per million output tokens. That shows OpenAI is maintaining a premium strategy for frontier models, while trying to convince businesses that the total cost can be justified through fewer tokens, fewer retries, and higher completion rates.
The real ambition behind this release is not simply to win another model leaderboard. It is to make ChatGPT, Codex, and the API into an agentic layer for the workplace. GPT-5.5 can take action across connected work tools, which means the model is no longer just an isolated chat window. It may gradually become an interface that cuts across email, documents, code repositories, spreadsheets, customer-support systems, and internal databases. If this direction holds, the value of an AI platform will expand beyond the model itself into permission management, data connections, task auditing, safety policies, and workflow integration.
This also explains why OpenAI devotes so much attention in its announcement to safety and cyber defense. GPT-5.5 is described as having stronger cybersecurity capabilities. OpenAI also classifies its biochemical and cyber capabilities as High under its Preparedness Framework, while strengthening classifiers and restrictions for high-risk cyber requests. This is not merely a public-relations addendum. It is a precondition for the commercialization of agentic AI. When a model can operate tools, read internal data, write and repair code, its usefulness and risk rise together. Companies will not entrust core work to a model that merely chats. But nor will they entrust core work to an agent that cannot be audited, constrained, or trusted.
The release of GPT-5.5 comes as American AI companies are collectively pushing the battlefield toward agentic work. Anthropic’s official announcement, “Introducing Claude Opus 4.7” (https://www.anthropic.com/news/claude-opus-4-7), similarly emphasizes stronger coding, agency, vision, and multi-step task capabilities, while making automated detection and blocking of high-risk cyber use cases a prominent theme. Its narrative closely resembles OpenAI’s: frontier models are no longer just supposed to speak more fluently, but to maintain goals across long, multi-step, uncertain tasks.
Google’s route is more closely tied to its existing ecosystem. According to Google’s official blog post, “Gemini 3.1 Pro: A smarter model for your most complex tasks” (https://blog.google/innovation-and-ai/models-and-research/gemini-models/gemini-3-1-pro/), Gemini 3.1 Pro has been rolled out to the Gemini API, Vertex AI, the Gemini app, and NotebookLM, with complex task reasoning as a central selling point. In “Deep Research Max: a step change for autonomous research agents” (https://blog.google/innovation-and-ai/models-and-research/gemini-models/next-generation-gemini-deep-research/), Google presents autonomous research agents, MCP support, and native visualization as selling points for long-horizon research workflows. By comparison, OpenAI’s advantage lies in ChatGPT’s consumer-scale entry point and Codex’s place in the minds of developers. Google’s advantage lies in Workspace, cloud infrastructure, search, Android, and a vast distribution surface. The contest between them will not be settled only by model scores. It will depend on who can embed AI into more everyday points of work.
Seen internationally, GPT-5.5 must also be understood against three different paths emerging across the United States, China, and Europe. China’s DeepSeek announced in its official document, “DeepSeek V4 Preview Release” (https://api-docs.deepseek.com/news/news260424), that DeepSeek-V4 Preview had been open-sourced, highlighting a one-million-token context window, DeepSeek-V4-Pro’s 1.6 trillion total parameters and 49 billion active parameters, and the more efficient DeepSeek-V4-Flash version. That contrasts with OpenAI’s closed, premium, enterprise-paid model. The strategic significance of Chinese models lies not only in raw capability but also in open-source access, lower costs, and adaptation to domestic compute, all of which reduce dependence on American models and Nvidia hardware. If the moat of American firms is productization and cloud ecosystems, the Chinese challenge is pressure on the cost curve and supply-chain constraints.
Europe presents a third posture. Mistral AI’s official announcement, “Introducing Forge” (https://mistral.ai/news/forge), proposes allowing companies to build frontier-grade AI models based on their own proprietary knowledge, while its product messaging emphasizes enterprise data privacy, deployment control, and full ownership. That reflects Europe’s long-standing concern with data sovereignty and regulatory control. For many financial, manufacturing, public-sector, and regulated industries, the strongest model may not always be the only answer. Whether a system can be deployed locally, in a private cloud, or inside a tightly controlled environment, and whether data can remain within corporate boundaries, may matter just as much.
If GPT-5.5 can reliably complete vague, multi-step, cross-tool tasks in the way OpenAI describes, software development and knowledge work will be among the first areas affected. Coding agents have already begun to change the division of labor inside engineering teams. More first-pass implementation, refactoring, testing, bug fixing, and documentation will be handled first by AI; human engineers will spend more time on architecture, product judgment, security review, and final accountability. This does not mean engineers will simply be replaced. It means their work will be re-layered. Those who can direct AI agents, verify outputs, and integrate them into organizational workflows may become more valuable; those relying only on narrow, easily replicated skills may face pricing pressure.
The same logic applies to consulting, law, finance, research, and operations. AI can compress the time needed for information gathering, preliminary analysis, drafting, and formatting, thereby changing the pricing logic of professional services. Work that used to accumulate billable hours may increasingly be priced by outcome, speed, or risk assumption. That will confront large consulting firms, law firms, investment banks, and internal corporate staff functions with the same question: if AI can perform more foundational work, how many junior employees does an organization still need in order to train the senior experts of the future? That is one of the unresolved management problems of the agentic AI era.
Yet GPT-5.5’s prospects should not be mistaken for frictionless automation. The greatest challenge of agentic AI is not a single wrong answer. It is the gradual drift of a long task in a way that appears plausible at each step. When a model can operate tools, modify documents, send requests, or change code, small errors can become process failures. The real cost of adopting GPT-5.5 includes not only API pricing, but also permission design, data governance, audit logs, human review, error recovery, and employee training.
There is also still a gap between benchmarks and practice. OpenAI’s published figures show GPT-5.5 leading or approaching competitors across several tasks, but different models have different strengths. In OpenAI’s listed public results for SWE-Bench Pro, for instance, Claude Opus 4.7 still outperforms GPT-5.5. In some research or financial tasks, Pro-tier models, competing systems, and tool configurations may affect outcomes. Enterprise buyers will not look only at a single leaderboard. They will ask whether a model is stable on their own data, inside their own processes, and under their own risk constraints.
The release of GPT-5.5 brings the AI industry into a more realistic and more complicated phase. Model capability still matters, but the real competition will increasingly depend on institutional capability: who can provide a more stable agent framework; who can connect securely to enterprise data; who can support large-scale daily use at acceptable cost and latency; and who can persuade governments and regulated industries to accept models in high-risk work. OpenAI has an early position through ChatGPT, Codex, and its API. Anthropic competes on safety and long-task performance. Google relies on Workspace, cloud, and search. DeepSeek and other Chinese firms challenge closed models with open-source access and cost pressure. Europe’s Mistral-style route pushes sovereignty, controllable deployment, and enterprise data boundaries to the foreground.
The industrial meaning of GPT-5.5 is not that it ends the model race. It is that it redefines the question. Future AI products will not merely be asked, “What does it know?” They will be asked, “What can it complete for an organization, under what constraints, and who is responsible when it fails?” Once AI begins operating computers like a colleague, technology companies are no longer just selling intelligence. They are selling a new order of work. GPT-5.5 brings that order closer into view, but it also reminds the market that the hardest part may not be making models smarter. It may be teaching organizations how to redistribute power among speed, trust, and responsibility.
GPT-5.5 looks like a technology launch, but it is better understood as a stress test for corporate systems. When a model can understand vague instructions, call work tools, write code, organize research, and generate deliverables, the question of enterprise AI adoption changes from “Should it be used?” to “Which workflows can be handed to AI, which steps require human responsibility, and which data must never leave controlled boundaries?” These questions will not disappear as model scores rise. On the contrary, they will become more urgent as models become more capable.
From a market perspective, OpenAI is trying to position GPT-5.5 as the standard entry point for advanced knowledge work and enterprise agent tasks. If that path succeeds, ChatGPT will be more than an application; it may become a new interface for work. Codex will be more than a programming assistant; it may become a resident member of the software-development process. But competitors will not stand still. Anthropic will continue to compete for enterprise trust through safety and long-task ability. Google will push AI deeper through cloud, Workspace, and search. Chinese models will squeeze pricing with open-source access and cost efficiency. European companies will turn data sovereignty and controllable deployment into differentiating strengths.
The real test of GPT-5.5, therefore, will not be its launch day, but the enterprise adoption curve over the months and years ahead. If it can consistently reduce repetitive work, lower error rates, and shorten development and research cycles, it will help move AI from assistant software into organizational infrastructure. If it repeatedly runs into reliability, governance, and accountability problems, the market will once again remind Silicon Valley that intelligence is not the same thing as productivity. That is what makes this race worth watching: the more AI models resemble employees, the more companies will have to manage them like employees.

Leave your name and email to receive future blog updates and product insights.
AI News | Editor: Sandy Google announced this week that its redesigned, AI-powered Google Finance is...
Read Article
AI News | Editor: Sandy Anthropic released the latest update to Claude Managed Agents on May 6, 2026...
Read Article
Turning AI Workflows for Finance Teams into Prompts for Content and Business Tasks OpenAI Academy’s...
Read Article
AI News | Editor: Sandy On May 12, 2026, Google announced Googlebook in its official blog post, “Int...
Read Article
In mid-May 2026, Anthropic shifted the commercial story around Claude from “model capability” toward...
Read Article
Many small business owners, independent professionals, and solo operators are already using AI conte...
Read Article
Series H Turns Anthropic From a Model Company Into an Infrastructure-Scale AI Player Anthropic annou...
Read Article
How Does AI Understand Your Brand? Your website may already explain your company, services, case stu...
Read Article
Over the past three months, Pimker ran a three-phase study on AI citations: 320 websites, 50 industr...
Read Article
AI search is a way of using artificial intelligence to help people find information, understand a qu...
Read Article
E-E-A-T is a concept Google uses to evaluate content quality. It stands for Experience, Expertise, A...
Read Article
AI search exposure means the chance that your brand, website, product, service, or content appears i...
Read Article
AI search probably will not completely replace traditional search, but it will change how many peopl...
Read Article
When a new website goes live, many businesses assume, “Now that the site is done, customers should s...
Read Article
Yes. AI search can be very helpful for B2B businesses, especially when the product or service is exp...
Read ArticleWe make your brand easier for AI to discover and recommend. From brand positioning and content structure to a strategic update cadence, Pimker turns your website into a system that supports long-term visibility.
Contact Us
© Pimker 2026 AI marketing software built for modern businesses All rights reserved.